- 用語
- 機械学習
- モデル
- 回帰
- 分類
- データセット(dataset)
- 中間層
- 過学習(Overfitting)
- 特徴量(feature)
- 交差検証(cross-validation)
- パラメーター(parameter)
- スタッキング(stacking)
- 正規分布(normal distribution)
- 正規分布曲線(bell curve)
- アルゴリズム
- 二分探索法
- 幅優先探索
- ham
- 離散値
- 決定木(decision tree)
- ランダムフォレスト(random forest)
- ロジスティクス回帰
- カテゴリー変数(categorical feature)
- 歪度(skewness)
- 尖度(skewness)
- パラメータ
- ハイパーパラメータ
- box-cox tranform(べき正規変換)
- get_dummy(ダミー変換)
- パイプライン(pipeline)
- クラスタリング(clustering)
- 外れ値(outlier)
- スケーリング(scaling)
- 標準化(z-core normalization)
- 正規化(min-max normalization)
- 次元削減(Dimensionality Reduction)
- 部分集合(subset)
- データラングリング(data-wrangling)
- タイムスタンプ(timestamp)
- サンプリング(sampling、標本抽出)
- ホワイトノイズ(white noize)
- ランダムウォーク(random walk)
- 特徴抽出(feature extractor)
- CNN(畳み込みニューラルネットワーク)
- バッチ(batch)
- 学習回数
- 多項式(Polynomial)
- 多項式回帰(Polynomial Regression)
- imputer(代入法)
- 自然対数の底(ネイピア数)
- sequece(シーケンスデータ)
- ネットワーク(network)
- ニューラルネットワーク(neural network)
- 正則化(Regularization)
- LightGBM
- 協調フィルタリング(Collaborative filtering)
- ピボットテーブル(pivot table)
- SVD(特異値分解, singular value decomposition)
- 線形(linear)
- N-gram
- 重み(weight)
- トランザクション
- よく参考にさせていただいているサイト
用語
- 一言で
- わかりやすい例
- ポイント
- 参照
- 実装例
機械学習
- コンピューターに学習させて、分類とか予測をさせる
- 大量の画像から顔認識する(分類)、過去の株価データから未来の株価を予測(回帰)
- 入力→学習→出力
- https://ainow.ai/2022/02/01/262467/#i-4 機械学習理論の考え方をゲームを使ってみてみる | NHN テコラス Tech Blog | AWS、機械学習、IoTなどの技術ブログ
モデル
- 入力したデータを基に、結果を導く仕組み
- 音声の文字起こし
- https://www.dsk-cloud.com/blog/what-is-machine-learning-model
回帰
- 未来の数値を予測
- 過去の気温から明日の気温を予測する
- 【3分で分かる】回帰問題と分類問題の違い - Qiita
分類
- どのグループに属するかを予測
- 特徴からどの犬種かを当てる
- 【3分で分かる】回帰問題と分類問題の違い - Qiita
データセット(dataset)
- データの集合
- 過去10年分の株価
- 特になし
中間層
- 入力層と出力層の間
- なし
- 下の画像
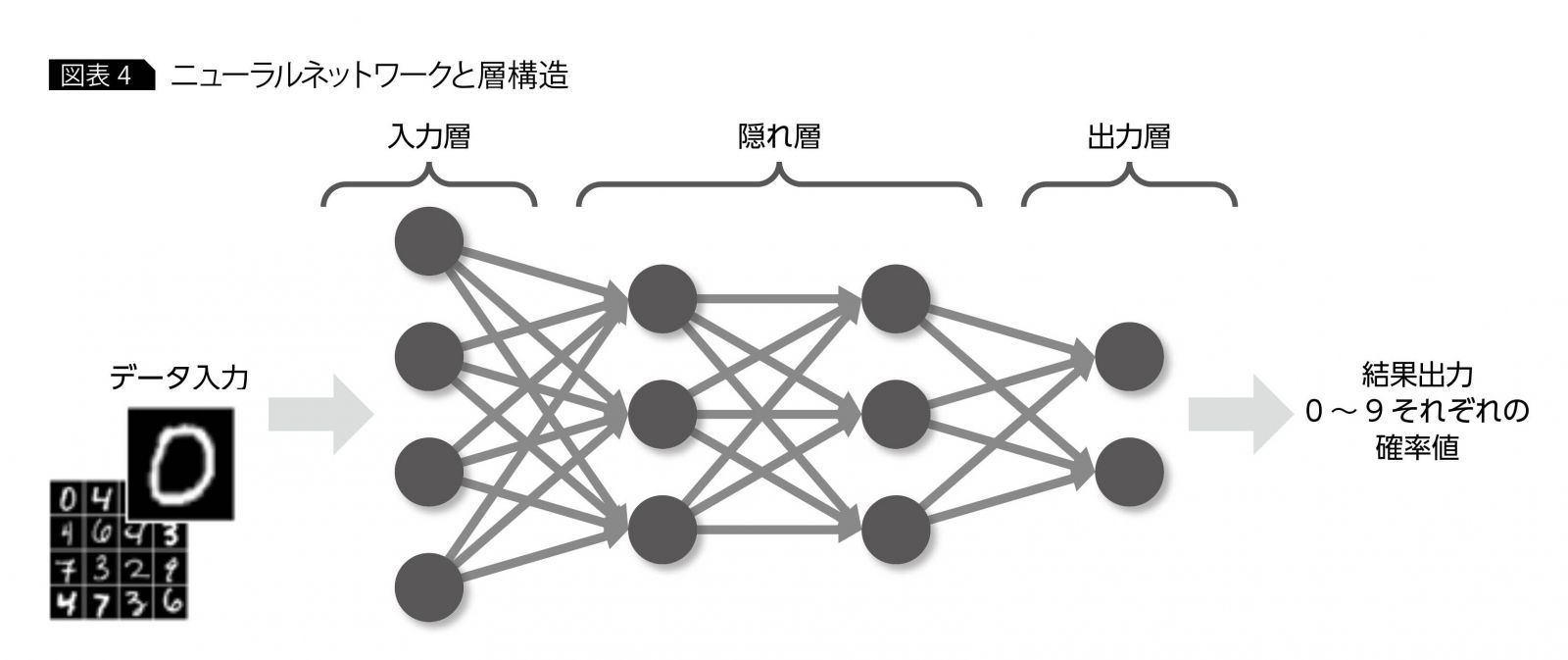

過学習(Overfitting)
- 手元にあるデータにぴったりと合いすぎて、使えない予測をすること
- なし
- https://toukei-lab.com/over-fitting
特徴量(feature)
- 予測の手掛かりとなる数値
- 人間でいうと、身長や体重、年齢、性別
- https://www.tryeting.jp/column/1000/
交差検証(cross-validation)
- 予測モデルの精度を図る
- 「靴を投げて明日の天気を予報する」予測モデルの精度を図る
- クロスバリデーションでモデル選択の過学習を回避!変数選択で重要な理由とは?|いちばんやさしい、医療統計
パラメーター(parameter)
- 外から入ってくる値
- (URLパラメーター)URLのなかの「?」以降の文字列
- https://wa3.i-3-i.info/word1443.html
スタッキング(stacking)
- 複数の学習モデルを使う
- 線形回帰×ランダムフォレスト
- https://bigdata-tools.com/stacking/
正規分布(normal distribution)
- 左右対称で平均を中心に左右に裾野をもつ、富士山のような形をしているカーブ
- 偏差値
- 統計手法は、正規分布を前提としている
- https://bigdata-tools.com/normal-distribution/ https://www.albert2005.co.jp/knowledge/statistics_analysis/probability_distribution/normal_distribution
正規分布曲線(bell curve)
- 正規分布を曲線にしたもの
- 左右対称の山みたいなグラフ
- X軸の要素が連続しているから、曲線を描ける
- https://www.albert2005.co.jp/knowledge/statistics_analysis/probability_distribution/normal_distribution
- ヒストグラムに正規分布曲線を重ねたそれっぽいグラフを描きたい! - ぺーぱーの日々
アルゴリズム
- 計算や処理の手順
- 大根のいちょう切りの手順
- コンピュータにも限界があるから、効率的に仕事をしてもらうための手法が必要
- アルゴリズムとは?プログラミングにおいての重要性、代表的なアルゴリズムの種類を紹介
必須教養!?プログラミング“金メダリスト”に学ぶ「アルゴリズム」【橋本幸治の理系通信】(2022年3月30日) - YouTube
二分探索法
- 2択を繰り返して答えにたどり着くアルゴリズム
- 1~100までの数字を当てる
- データが順番に並んでいないと使えない
- https://wa3.i-3-i.info/word1614.html
幅優先探索
- 出発点から順番にしらみつぶしにいくアルゴリズム
- 乗り換え案内
- 深いところがあると、時間がとられる
- 必須教養!?プログラミング“金メダリスト”に学ぶ「アルゴリズム」【橋本幸治の理系通信】(2022年3月30日) - YouTube
ham
- スパムメール(迷惑メール)でないもの
- 迷惑メール→spam、そうでないメール→ham
- 迷惑メールの分類
- http://www-optima.amp.i.kyoto-u.ac.jp/papers/bachelor/2004_bachelor_inoue.pdf
離散値
- 連続していない値
- 男性→1、女性→0とする
- 整数で表す(0.5とかの中間値を取らない)
- 機械学習においての分類とは?代表的なアルゴリズムやメリットも解説! | AI専門ニュースメディア AINOW
決定木(decision tree)
- 枝分かれをして答えを導き出す
- 野球をするか、を条件分岐して決める
- リスクマネジメントで使われる
- https://ainow.ai/2022/02/01/262467/#i-4
ランダムフォレスト(random forest)
- 複数の決定木を使って、多数決して決める
- 導き出したいのは1つ
- 単独の決定木よりも優れた分析結果が得られることが多い
- https://ainow.ai/2022/02/01/262467/#i-4
ロジスティクス回帰
https://gmo-research.jp/research-column/logistic-regression-analysis
https://gmo-research.jp/research-column/logistic-regression-analysis
- 「ある事柄が起きるか起きないか」を分類するためのアルゴリズム
- 喫煙と飲酒の量に応じて、がんが発生する確率を予測
- 名前に「回帰」とあるけど、分類するためのもの
-
https://gmo-research.jp/research-column/logistic-regression-analysis
カテゴリー変数(categorical feature)
- 量では表せない変数
- 性別とか宗教
- 量的変数に対して、質的変数とも呼ばれる。
- https://vector-ium.com/stats-variable/
歪度(skewness)
- 分布の歪み度合い
- 左重心の富士山
- 数値データと記号データの両方を扱うことができる.
- https://academic-support.jp/%E6%9C%AA%E5%88%86%E9%A1%9E/558/
尖度(skewness)
- 分布のとがり度合い
- つぶれた富士山
- 数値データと記号データの両方を扱うことができる.
-
https://academic-support.jp/%E6%9C%AA%E5%88%86%E9%A1%9E/558/
パラメータ
- モデルが勝手に調整してくれる数値
- バイアスとか、重みとか
- 勝手にやってくれる
- 【初心者】機械学習の〇〇データが分からない【図解】
ハイパーパラメータ
- 人間が調整する数値
- 学習回数とか
- プログラマーが決めないといけない
- 【初心者】機械学習の〇〇データが分からない【図解】
box-cox tranform(べき正規変換)
- 正規分布に変換する
- 過去のデータから将来のPM2.5の値を予測
- 線形回帰とかできないから
- https://toukei-lab.com/box-cox%E5%A4%89%E6%8F%9B%E3%82%92%E7%94%A8%E3%81%84%E3%81%A6%E6%AD%A3%E8%A6%8F%E5%88%86%E5%B8%83%E3%81%AB%E5%BE%93%E3%82%8F%E3%81%AA%E3%81%84%E3%83%87%E3%83%BC%E3%82%BF%E3%82%92%E8%A7%A3%E6%9E%90
get_dummy(ダミー変換)
- 質的変数を量的変数っぽく変換する
- 男を
0, 女を1のように変換したりする - 数値にしないと評価できない
パイプライン(pipeline)
- 学習ステップを自動化して、継続して実行する
- 特になし
- 予測精度を担保するために、学習そのものの精度をチャックする必要だからmake_pipelineをする
- コラム - グーグルのクラウドを支えるテクノロジー | 第70回 機械学習パイプラインにおける学習データの異常検知システム(パート1)|CTC教育サービス 研修/トレーニング
クラスタリング(clustering)
- 類似しているデータをグループ分けする
- 顧客のグループ分け
- 答えを渡す→分類、答えは渡さない→クラスタリング
- https://ledge.ai/clustering/
外れ値(outlier)
- 極端に大きい、小さい値
- [10, 8, 9, 7, 9, 500] で、500がいるのといないの(90.5 VS 8.5)
- ノイズとして処理される
- https://aiacademy.jp/media/?p=2267
スケーリング(scaling)
- 各次元の関係をわかりやすくする下準備
- 標準化、正規化が有名
- 単位が違う、桁が違うと比較できない
- AI Academy | 標準化と正規化
標準化(z-core normalization)
- 平均を0、標準偏差を1に変える
- ー
- ー
- AI Academy | 標準化と正規化
正規化(min-max normalization)
- 最大値を1、最小値を0に変える
- ー
- ー
- AI Academy | 標準化と正規化
次元削減(Dimensionality Reduction)
- 意味を保ったまま、データを要約したり、縮約したりする
- データの可視化
- 4次元よりも2次元のほうが、人間にはわかりやすい
- https://analysis-navi.com/?p=2175
-
部分集合(subset)
- ちっちゃな集団
- ー
- 全体の集合をfullsetと呼ぶ。subsetは、fullsetの一部。
- https://wa3.i-3-i.info/word15233.html
データラングリング(data-wrangling)
- 分析しやすいようにデータを処理する
- クリーニングとか、データ型の変換とか
- 元々、「馬とか牛を集めて飼いならす」の意味。
- ー
タイムスタンプ(timestamp)
- ある一点を表す
- 2022-06-08-19:45:55
- 時点→timestamp、期間→period
- ー
サンプリング(sampling、標本抽出)
- 母集団から標本を採ってくる
- 視聴率を図るために、200家庭に電話アンケート
- 母集団全体の特徴とか傾向を知るため
- ー
ホワイトノイズ(white noize)
- ある時点に発生する乱数
- 株価のチャート
- 確率的なばらつきを表すときに使う
- https://ai-trend.jp/basic-study/time-series-analysis/time-series-analysis-stationaly-noise/
ランダムウォーク(random walk)
- 未来がどう動くかは、過去の動きとは関係がない
- 過去の株価推移から未来の株価を予測するのは、無理
- 現時点で知りうる材料は、すでに株価に織り込まれていると仮定する
- ランダム・ウォーク|証券用語解説集|野村證券
特徴抽出(feature extractor)
- 予測に必要な特徴量を選抜
- ー
- ー
- ー
CNN(畳み込みニューラルネットワーク)
- ー
- ー
- 画像認識が得意
- ー
バッチ(batch)
- まとめて処理する
- 忙しくないときに、まとめてやろうか
- バッチサイズ=まとめて何個のデータを見せるか
- https://zenn.dev/nekoallergy/articles/ml-basic-epoch
学習回数
- データを何回見せたか
- ー
- ー
- 【初心者】ネコでも分かる「学習回数」ってなに?【図解】
多項式(Polynomial)
- 掛け算と足し算で成立している文字式
- 2x+yとか、2a**2-3b**2
- 項:+で区切ったときに得られるもの
- 多項式の全てがこれでわかる!多項式はこれで完璧だ!|高校生向け受験応援メディア「受験のミカタ」
多項式回帰(Polynomial Regression)
- 2つ以上の入力データを使って、数値を予測
- 身長、ウエスト、体脂肪…を使って、体重を予測
- ー
- https://qiita.com/tomoxxx/items/1045141b0219b3a21f32
imputer(代入法)
自然対数の底(ネイピア数)
- ー
- ー
- 1年間の合計金利が% になる銀行にお金を預けたら・・・
- https://atarimae.biz/archives/10256#1100
sequece(シーケンスデータ)
- 連続しているもの
- 順番に並んだデータをシーケンスデータと言う
- ー
- ー
ネットワーク(network)
- ニューラルネットワークを指すことが多い
- 本来は、網の意。
- ー
- ー
ニューラルネットワーク(neural network)
- 脳の神経回路の仕組みを模した分析モデル
- ディープラーニングの基本
- 入力層、中間層(モデル層)、出力層からなる
- https://www.soumu.go.jp/ict_skill/pdf/ict_skill_3_5.pdf
正則化(Regularization)
- 情報を追加する
- 目的は、過学習を防ぐため
- ー
- 正規化(Normalization)と正則化(Regularization) - Qiita
LightGBM
- 勾配ブースティングの流れを汲む機械学習手法
- Kaggleの上位者よく使っている
- ー
- https://rightcode.co.jp/blog/information-technology/lightgbm-useful-for-kaggler#LightGBM
協調フィルタリング(Collaborative filtering)
- 「もの」と「人」の類似度から、おすすめする
- ECサイトに表示される「この商品を見た人はこんな商品も見ています」
- ー
- 協調フィルタリングって何?商品のおすすめ機能を学…|Udemy メディア
ピボットテーブル(pivot table)
- 2つのカテゴリーのデータを集計したもの
- 売上管理表→だれが(従業員名)×なにを(商品分類)
- 予測
- Pandas入門講座|10.データ集計(pivot_table)の方法【PythonのライブラリPandas】 | キノコード
SVD(特異値分解, singular value decomposition)
- ある行列を直交行列と対角行列の積に分解する
- 次元削減手法のひとつ
- ー
ピアソンR相関(Pearson correlation、Pearsons' R correlation)
相関係数のこと
国語の成績と数学の成績の相関関係
散布図にしてみると可視化できる(1に近いと右上がり、-1に近いと右下がりの直線)
相関係数(Correlation Coefficient)/ピアソンの積率相関係数(PCC)とは?:AI・機械学習の用語辞典 - @IT
線形(linear)
- 比例の関係
- ガラスは、力を加えると、その大きさに伴い、変形が大きくなる
- 結果が予測しやすい
- 線形とは?1分でわかる意味、非線形との違い、線形的な材料、線形と剛性の関係
N-gram
- 文章を任意の文字数で分割する
- N=1→文章を1文字ずつ分割する
- ー
- 【自然言語処理】N-gramとは | AI Academy Media
重み(weight)
- より重要なものをを特別扱いする
- 加重平均が代表
- 加重平均の意味と計算方法
行列の対角化
- 任意の行列を、便利な性質をもつ対角行列に変換する
- ー
- ー
トランザクション
- 「ここからここまでワンセット」的な処理単位
- 商品を打ち込んで、代金を受け取って、商品を渡す=トランザクション
- ー